
Aims
- Understand basic GPU structure and how it works on Neural Network training
- 찍먹 on CUDA programming
Graphic Processing Unit
- Game Processing Unit
- Great Pucking expensive Unit
Hardaware Architecture Comparison
CPU
- Optimized for latency
- Handle many tasks at the same time
- Core
- Executes instruction cycle: fetch, decode, execute, write back
- Consists of Control unit, ALU, and Register
- They are powerful independents
- Cache
- Small memories on or close to cores
- Reduces memory transaction bottlenecks between CPU and system memory
- CPUs do all the thing what we want computers do
- Why don't we keep increasing this awesome cores? -> HEAT🔥
- We need smaller and efficient processors, very many of them
GPU
- Optimized for Throughput
- A lot of cores do one instruction
- Streaming Multiprocessors
- Consists of a lot of simple cores
- All cores execute the same command
- L1, L2 and GPU memory
- Smaller at its size
- Bigger at its bandwidth
- CPU: 24-32 GB/s -> GPU: 100-200 GB/s
Differences between CPU and GPU
- Powerful but Few cores vs Weak but Many cores
- Latency vs Throughput
- Many tasks vs Vast input
- Serial vs Parallel
How GPUs speed up NN training
- Large memory bandwidth
- Shared memory
- Parallel computing
CUDA
- CUDA: Compute Unified Device Architecture
- A parallel computing platform and programming model created by NVIDIA
- SIMT: Single Instruction Multiple Threads
- CUDA extensions available in C, C++, and etc
Structure
- Kernel: Functions that run on GPU
- Thread: Lowest entity of execution
- Is assigned to a single core
- Block: Lowest entity of program
- Group of threads
- Is assigned to a single SM
- Grid
- Group of blocks
- Kernel calls generate grids
Kernel
Why
__global__can't return value?
There's no way in CUDA (or on NVIDIA GPUs) for one thread to interrupt execution of all running threads
Example - addOne
- On
__host__- Initialize an array
- Copy memory from Host to Device
- Block and Grid dimensions
- Launch Kernel
- Copy memory from Device to Host
- Release memory on device
- On
__device__- Define a function
IFensures that no extra threads execute kernel
#include<stdio.h>
#include "cuda_runtime.h"
__global__ void addOne(int* a, int N) {
int i = threadIdx.x;
if (i < N)
a[i] = a[i] + 1;
}
__host__ int main() {
// Initialize an array
int array_size = 5;
int *h_a = (int*)malloc(array_size * sizeof(int));
for (int i = 0; i < array_size; i++)
h_a[i] = i;
// Allocate arrays is Device memory
int *d_a;
cudaMalloc((void**)&d_a, array_size * sizeof(int));
// Copy memory from Host to Device
cudaMemcpy(d_a, h_a, array_size * sizeof(int), cudaMemcpyHostToDevice);
// Block and Grid dimensions
dim3 grid_size(1);
dim3 block_size(array_size);
// Launch Kernel
addOne<<<grid_size, block_size>>>(d_a, array_size);
// Copy memroy from Device to Host
// Release memory on device
cudaMemcpy(h_a, d_a, array_size * sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(d_a);
for (int i = 0; i < array_size; i++)
printf("%d ", h_a[i]);
return 0;
}
Matrix Multiplication w/ Multiple Threads
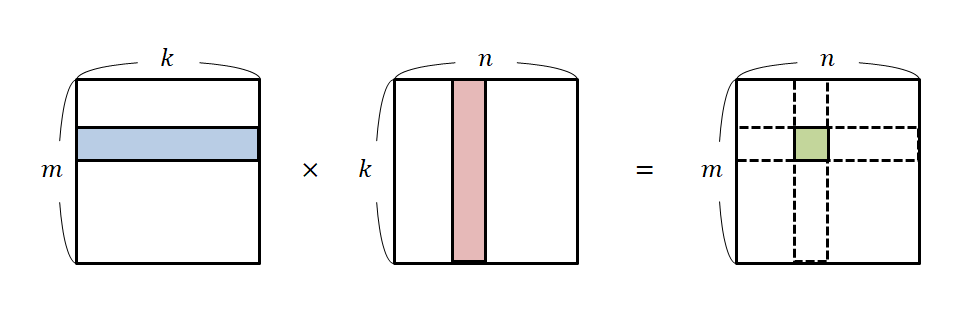
- Multiple threads can simultaneously execute (the same) kernel program.
- Assign each dot product of matrix multiplication to a thread
Thread Indexing
gridDim: # of blocks in a grid- organized into 1-dim, 2-dim or 3-dim arrays of blocks
blockIdx: id of the block in a gridblockDim: # of threads in a block- organized into 1-dim, 2-dim or 3-dim arrays of threads
threadIdx: id of the thread in a block- Global thread Id in Grid =
blockDim*blockId+threadId
Code implementation
- Calculate the row index of matrix A
- Calculate the column index of matrix B
- Doc product between row of A and column of B
- Map to result matrix C
__global__ void matrixMul(float *A, float *B, float *C, int M, int K, int N) {
// calculate the row index of matrix A
int row = blockDim.y * blockIdx.y + threadIdx.y;
// calculate the column index of matrix B
int col = blockDim.x * blockIdx.x + threadIdx.x;
float tmpSum = 0;
if (row < M && col < N) {
// Dot product
for (int i = 0; i < K; i++) {
tmpSum += A[row * K + i] * B[(i * N) + col];
}
// Map to result matrix
C[row * N + col] = tmpSum;
}
}
Matrix Multiplication w/ Shared memory
{kind=link}
- Threads of a block load tiles to Shared memory
- Execute batch matrix multiplication
- Check no threads steps to next tile before complete batch matrix multiplication
- All threads store the calculatedvalue in the resulting matrix and the thread ends
Shared Memory
- global memory of a CUDA device is implemented with DRAMs
- And DRAMs are slow to access
- Shared memory is small but fast.
- Each block has its shared memory
- Threads can communicate with each other using the shared memory
Memory optimization
In case of 4 * 4 Matrix
- Without tiling
- A thread access a row and a column of matrices
- 8 accesses per thread
- 32 accesses per block(4threads)
- With tiling
- A thread loads two elements from each matrices
- 4 accesses per thread
- 16 accesses per block(4threads)
- Global memory access is reduced by TILE_WIDTH times
Code implementation
- Initialize the tile matrces on shared memory
- Calculate the row and column index per thread
- Load elements from global memory to tile matrices on shared memory
- If Out-Of-Range, load 0
- Synchronize threads until all threads finish loading tile matrices
- Execute dot product and sum to tmporary variable
- Synchronize threads until all threads finish dot product
- Move to next tile and repeat the process
- Map to result matrix
__global__
void matrixMulTiled(float *A, float *B, float *C, int M, int K, int N)
{
// Initialize matrix on shared memory
__shared__ float Asub[TILE_WIDTH][TILE_WIDTH];
__shared__ float Bsub[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x, by = blockIdx.y;
int tx = threadIdx.x, ty = threadIdx.y;
// Calculate the row and column
int row = by * TILE_WIDTH + ty;
int col = bx * TILE_WIDTH + tx;
float tmpSum = 0;
for (int i = 0; i < ceil(K / (float)TILE_WIDTH); ++i) {
// Load tile from global memory to shared memory
if ((row < M) && (i*TILE_WIDTH + tx < K))
Asub[ty][tx] = A[row*K + i*TILE_WIDTH + tx];
else
Asub[ty][tx] = 0;
if ((col < N) && (i*TILE_WIDTH + ty < K))
Bsub[ty][tx] = B[(i*TILE_WIDTH + ty)*K + col];
else
Bsub[ty][tx] = 0;
// Synchronize threads
// All elements of tile are loaded
__syncthreads();
// Calculate the dot product
for (int j = 0; j < TILE_WIDTH; j++) {
tmpSum += Asub[ty][j] * Bsub[j][tx];
}
// Synchronize threads
// Ensure all calculations are done
__syncthreads();
// Move to next tile
}
// Map to result matrix
if ((row < M) && (col < N))
C[row*K + col] = tmpSum;
}
Ending
- Parallel computing is very complex
- It was the reason why my code always spit out so many
WARNINGs andERRORs - To be a "engineer" in ML/DL field, need strategy to debug and redcue error
- Personally, Trying to apply TDD-like development in ML field
